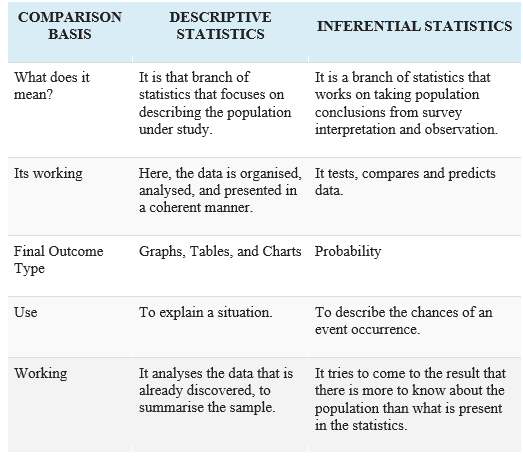
Descriptive statistics are destined to explain the fundamental characteristics of the results of a particular study. They provide crisp summaries of the findingsand the metrics. This type of statistics is based on almost all quantitative data analysis, coupled with a basic assessment of the graphics. However, inferential statistics are indeed different from descriptive statistics as in descriptive numbers; one normally explains what the data is or what it indicates and when using inferential statistics, one attempts to derive the results that go to the extent of the facts at hand. For example, we employ inferential statistics to predict whatever the population would think based on the survey data. However, the complexity of the subject leads students to go for our descriptive statistics assignment help.

If you attempt to explain a vast number of findings using a single measure, you risk misinterpreting the data or missing valuable information. The batter’s strikeout rate does not indicate if he is making home runs or singles. It’s impossible to know whether she’s been in a rut or on a roll. Similarly, the grades do not show whether the student took challenging or simple classes or whether the courses were in their main area or from other disciplines. Despite these pitfalls, descriptive statistics offer a valuable description that can be used to measure individuals or other units, and so our descriptive statistics assignment help fetches ‘A’ grades for every student!
Online Assignment Help
Custom Essay Help
Dissertation Writing Service
Univariate analysis entails looking at one variable at a time in all instances. We usually consider three main characteristics of a particularvariable:
In most cases, we can use all three of these features to characterise each of our study's variables.
As per our descriptive statistics dissertation help experts, the intensity of individual values or sets of values for the variable is summarised in the distribution. The most basic distribution list down everyvariable's value as well as the number of people who had that value. For example, mentioning the amount or per cent of students in each of the threeyears of college is a popular way to explain the distribution of college students. Alternatively, we may mention the amount or ratio of females and malesto define gender. In such cases, the vector has a small enough number of values that we can list them all and count how many sampleschematichas. But what about a predictor like wages or grade point average? There may be a vast number of potential values for these variables, with just a few individuals getting each one. For this case, we divide the raw scores into divisions based on significance scales. For example, we can look at a GPA based on letter grade ranges. Alternatively, we might divide wages into four or five different ranges.
Here is an example:
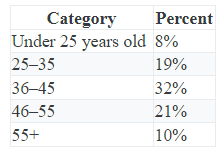
A distribution's central tendency is an approximation of the "middle" of a set of values. There have been three primary types of central tendency projections:
The most widely used way of explaining central inclination is the mean or average. The Median is the value that appears right in the centre of a set of values. It can be calculated by listing all of the points in numerical order and then locating the result in the sample's middle. The Mode is the value that appears the most often in the series of results. You will calculate the mode by reordering the valueas seen above and then counting each of them. It is the most often used value.
Here is our recently solved question—


As per our descriptive statistics assignment help experts, the distribution of values across the central tendency is referred to as dispersion. The distribution and the standard deviation are two typical metrics of dispersion. The spectrum is essentially the difference between the highest and lowest values. Since an outlier may significantly exaggerate the distribution (as in this case, wherein a single outlier point of 36 spreads out from the majority of the values), the Standard Deviation is a much more precise and thorough measure of dispersion.
Apart from univariate statistics, there are two more, namely, bivariate statistics and Multivariate statistics. To understand them or to make an assignment on any of them, do avail of our descriptive statistics dissertation help.
All descriptive statistics are central tendency'smetrics or indicators of variability, also recognized as measures of dispersion. Measures of core trend are concerned with the median or middle values of sets of data, while measures of uncertainty are concerned with the data's dispersion. Such two steps employ diagrams, general discussions, and charts to aid in the comprehension of the data being studied. Measures of central inclination define the centre place of a continuum for a data set. The mean, average, or Mode, which calculates the most typical trends of the examined data set, is used to define the occurrence of each data point in the distribution. To know more, avail of our descriptive statistics assignment help.
There are several descriptive figures to choose from. To list a few, the median, first quartile, mean, mode, kurtosis, skewness, standard deviation, and third quartile all provide information about the data.
Descriptive statistics are crucial as it can be complex to imagine what the data would display if we just viewed it as raw data, especially if there had been a lot of it. As a result, descriptive statistics helps one to view data in an effective manner, making data analysis dissertation help easier.
The features of a data set are summarized using descriptive statistics. You may use inferential statistics to formulate a theory to see if the data is generally applicable to a larger population.
Descriptive figures are restricted in that they can only be used to render summaries of the persons or items that have been calculated. You can't extrapolate the details you've obtained to other individuals or objects that isusing evidence from a survey to assume population parameters.
24 X 7 Support
100+ Subjects Covered
2000+ Ph.D Experts
My Assignment Services believes in the efficient assignment and dissertation writing service that is once you are here, you don’t have to go anywhere. We have a talent pool of highly qualified experts in all disciplines and their branches, including data science, agriculture, and other technical and non-technical stuff. Apart from this, our service is also student-friendly in many other aspects
Therefore, take the benefits of our confidential and affordable data statistics assignment help from My Assignment Services and remain stress-free. Fill the form now!
1,212,718Orders
4.9/5Rating
5,063Experts
Turnitin Report
$10.00Proofreading and Editing
$9.00Per PageConsultation with Expert
$35.00Per HourLive Session 1-on-1
$40.00Per 30 min.Quality Check
$25.00Total
FreeGet
500 Words Free
on your assignment today
Check out what our Student community has to say about us.
Request Callback
Doing your Assignment with our resources is simple, take Expert assistance to ensure HD Grades. Here you Go....

